
% だらけになった日本語 URL を解読してみる【パーセントエンコーディング】
日本語の入った URL をコピーしたときに、% がたくさん入った文字列になってなぜだろうと思ったことはありませんか?
例えば Wikipedia の URL などは日本語が入っているので、
https://ja.wikipedia.org/wiki/%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%9F%E3%83%B3%E3%82%B0コピーをした際などにこのような文字列になってしまうことがあります。
今回はなぜそのようなことが起こるのか、またそのような文字列を解読する方法を探ってみます。
なぜこのようなことが起こるのか
URL の中で使用できる文字は限られています。使用できない文字は、何らかの方法で使用できる文字に変換してあげないといけません。
例えば : (コロン) のような文字は、http: のように URL の中で特別な意味で使われるので、: という文字そのものを URL の中で使うことはできません。
試しに、アルファベットで「colon」と検索するときと、記号で「:」と検索するときを比べてみましょう。
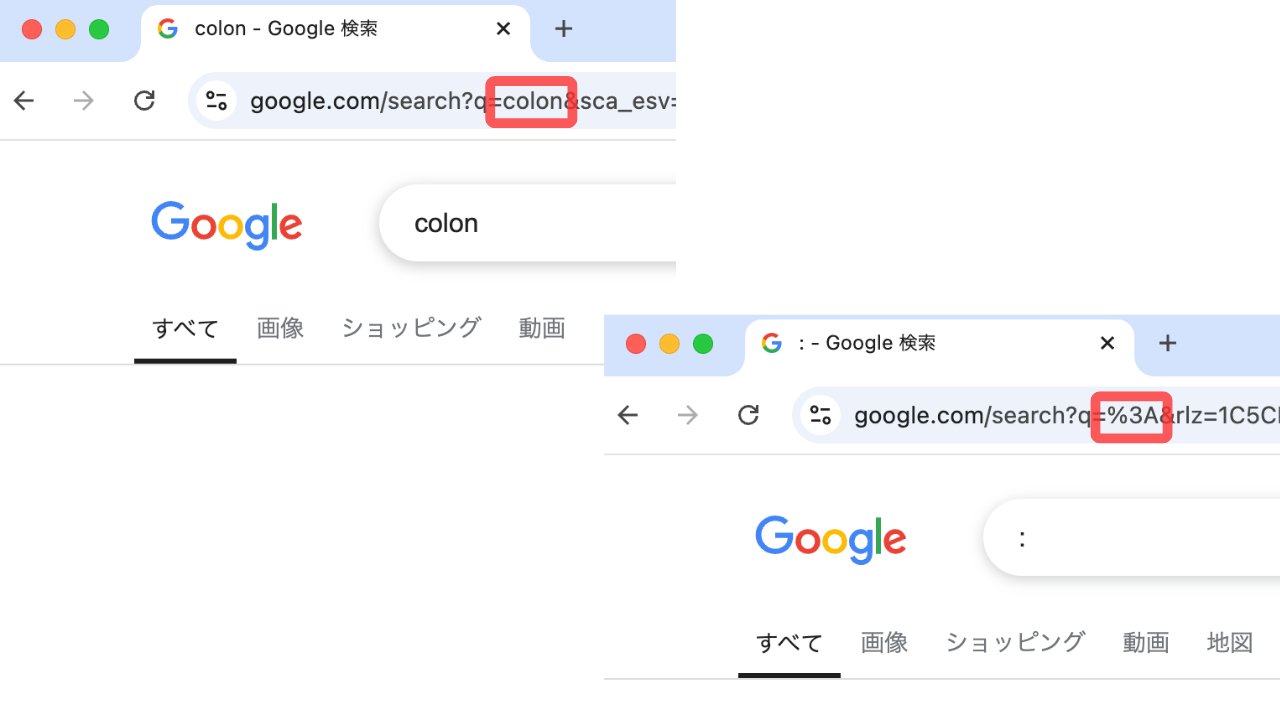
アルファベットで検索した際は文字列がそのまま入っていますが、記号で検索した際は %3A に変わっているのがわかります。
次は、日本語で検索してみます。検索した段階では日本語で表示されていますが、コピーして貼り付けると % を含む文字列に変わってしまいました。
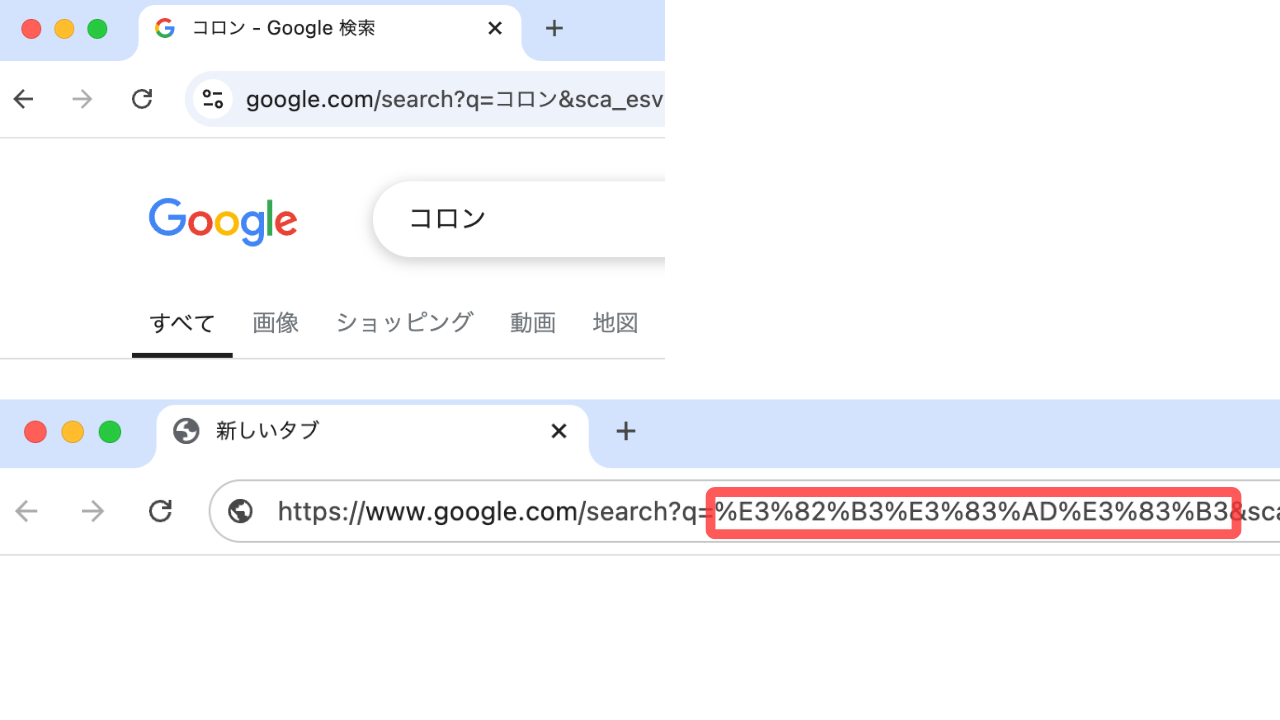
このように、URL の中で使えない文字を、使える文字に変換して表現することを一般に URL エンコード などというようです。URL エンコードの手法として、% の後に 2 桁の 16 進数を置くことで文字を表現する方法は パーセントエンコーディング と呼ばれます。
% の文字列を解読してみる
では、冒頭の URL の
%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%9F%E3%83%B3%E3%82%B0
という文字列を解読してみましょう。
準備: 16 進数 → 2 進数 の変換
パーセントエンコーディングでは、% の後に 2 桁の 16 進数を並べているのでした。
あとで扱いやすいよう、この 16 進数を 2 進数に変換しておきます。
最初は E3 です。
Eは 10 進数の14ですから、2 進数だと1110となります。3は 10 進数の3ですから、2 進数だと0011となります。
よって E3 は 11100011 となります。
この要領で全て変換すると下のようになります。1 バイト (= 8 ビット、2 進数の 8 桁) ごとに空白で区切っています。
11100011 10000011 10010111 11100011 10000011 10101101
11100011 10000010 10110000 11100011 10000011 10101001
11100011 10000011 10011111 11100011 10000011 10110011
11100011 10000010 10110000
変換のステップ
では、この 11100011... のような数字がどのように「あ」などの実際の文字に結びついているのでしょうか?
その方法は本来さまざまですが、ここでは現在多くの環境で使われていると思われる UTF-8 による方法を紹介します。やや複雑ですが、文字と数字を対応づけている Unicode というルールがあり、さらにその数字の並びを変形する UTF-8 という仕組みが存在します。
したがって、解読する際は、UTF-8 → Unicode → 実際の文字 という順を辿る必要があります。
UTF-8 → Unicode の変換
UTF-8 で表された数字の列を Unicode に変換するやり方ですが、
0xxxxxxx110xxxxx 10xxxxxx1110xxxx 10xxxxxx 10xxxxxx11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
のいずれかのパターンに当てはめた後、x の部分だけを取り出して並べればよいです。
今回の数字列の最初を見てみると 11100011 となっています。上の表を見れば、これは 3. のパターンに合致するので、3 バイト分をひとまとまりとしてみれば良いことがわかります。
3 バイト取り出すと 11100011 10000011 10010111 でした。
ここから x の部分を抜き出せば 0011 000011 010111 です。16 進数に変換すれば、30 D7 となります。
これで Unicode が得られました。
この要領で全て変換すると下のようになります。
| UTF-8 (2 進数) | Unicode (2 進数) | Unicode (16 進数) |
|---|---|---|
11100011 10000011 10010111 | 00110000 11010111 | 30 D7 |
11100011 10000011 10101101 | 00110000 11101101 | 30 ED |
11100011 10000010 10110000 | 00110000 10110000 | 30 B0 |
11100011 10000011 10101001 | 00110000 11101001 | 30 E9 |
11100011 10000011 10011111 | 00110000 11011111 | 30 DF |
11100011 10000011 10110011 | 00110000 11110011 | 30 F3 |
11100011 10000010 10110000 | 00110000 10110000 | 30 B0 |
Unicode → 文字 の変換
あとは Unicode に対応する文字を対応表から探せば良いだけです。
対応表はこちらを参照しましょう。
https://ja.wikipedia.org/wiki/Unicode一覧表
30 D7 ならば U+30D7 のように表されているので、「Unicode一覧 3000-3FFF(U+3000からU+3FFFまで)」に進んで探していきます。
U+30D7 に対応する文字を探していくと、それは「プ」でした!
・・・というわけで、この要領で変換を行っていくと文字をすべて解読することができます。
今回の解読結果
| 元の文字列 | Unicode | 実際の文字 |
|---|---|---|
%E3%83%97 | 30 D7 | プ |
%E3%83%AD | 30 ED | ロ |
%E3%82%B0 | 30 B0 | グ |
%E3%83%A9 | 30 E9 | ラ |
%E3%83%9F | 30 DF | ミ |
%E3%83%B3 | 30 F3 | ン |
%E3%82%B0 | 30 B0 | グ |